Insights


Data science is a relatively new and vibrant field that integrates novel and traditional sources of data in creative ways to solve problems and inform decision-making. It has deep ties to the business world of finance, insurance, retail, and internet companies in modeling and shaping consumer behavior. However, as federal, state, and local governments and foundations become more data-driven, mission-driven research organizations like RTI International have a unique opportunity to harness the methods and energy of data science to help them solve social problems and inform public policy.
I spent the first 26 years of my career at RTI as a statistician involved in various entrepreneurial adventures, until I transitioned to be the Director of the Center for Data Science a little over 4 years ago. In that time, we’ve grown from 4 to a vibrant team of 22 data scientists, software developers, and visual designers. We’ve helped clients solve national and international problems, improved our local communities, published our work, and presented at conferences, universities, government agencies, and the White House. We’ve created open source tools and applications, become thought leaders in areas such as data-driven justice, and appeared in the local and national media. Along with our staff, our work has evolved from dashboards to deep learning, and from prototypes to fully deployed products. In essence, we’ve translated RTI’s mission to improve the human condition into our team’s cause of data science for social good.
Understanding The Problem
In this blog post, I’ll highlight one project that embodies our mission, is motivating to our team, and has received national attention. First, some context. On August 9, 2014, 18-year-old Michael Brown, a suspect in a convenience store robbery, was shot by police in Ferguson, Missouri. Protests of police brutality continued in Ferguson for more than a week. This was to be another episode in the nationwide debate around race and policing. This time, there were calls for better official data on police killings.
In March of 2015, President Obama said in response to his Task Force on 21st Century Policing, "Right now, we do not have a good sense, and local communities do not have a good sense, of how frequently there may be interactions with police and community members that result in a death.”
In October 2015, former Attorney General Loretta Lynch announced a pilot program to provide national, consistent data to track people killed in the process of arrest by US law enforcement. The Bureau of Justice Statistics (BJS) was to create a more robust version of their earlier program to count arrest-related deaths. From 2003 to 2011, BJS published annual data provided voluntarily by state reporting coordinators, who used a variety of methods to collect data. It was intended to be a Census of all deaths that occur in the process of arrest—from apprehension to detention, and all manner of deaths, not just police shootings.
A coverage study conducted by RTI for BJS indicated that the counts through 2011 were seriously underestimating the true number of arrest-related deaths, and eventually crowdsourced lists from the likes of The Guardian (The Counted) and The Washington Post (Fatal Force) appeared to be doing a better job. For a serious federal statistics agency, this was unacceptable.
Designing the Solution
BJS asked RTI to redesign their arrest-related deaths program using a hybrid approach—identifying potential arrest-related deaths through online media reports (Phase 1), and following-up with a survey of law enforcement agencies and medical examiner/coroners’ offices to confirm identified deaths, verify facts about the decedents, and find others not found through media review (Phase 2). BJS was looking for a single official way to count arrest-related deaths, and to provide an accurate, national, and consistent approach to data collection.
Once this project got underway, RTI’s criminologists and social scientists ran into a big problem: media alerts revealed that there were well over 1,000,000 relevant news stories to review per month! There were many human coders, huge Excel spreadsheets, and one big headache. There was no way we could do this project relying on humans alone. The data science problem became this: can we reduce human labor without reducing the accuracy of identified decedents?
To solve this problem, we developed an automated coding and classification pipeline of online media data using text analytics and machine learning techniques. A potential arrest-related death was determined by processing news articles through a successive set of filters, starting with the universe of all news articles and ending with unique events (see Figure 1). The pipeline identifies potential cases that can be subsequently verified by human coders to form a comprehensive and timely count of arrest-related deaths.
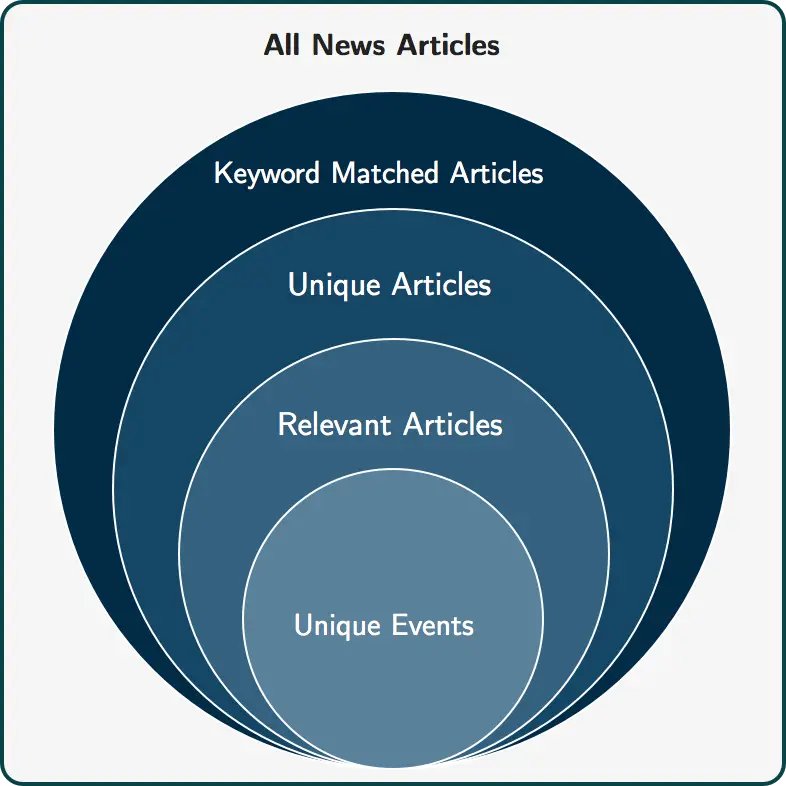
Tens of thousands of articles were ingested nightly, and various text processing steps were applied (e.g., deduplication, named entity extraction, and relevancy classification) (see Figure 2). An initial set of articles was manually reviewed and coded, and this information was used to train an ensemble of machine learning classifiers, including logistic regression, decision trees, and a neural network.
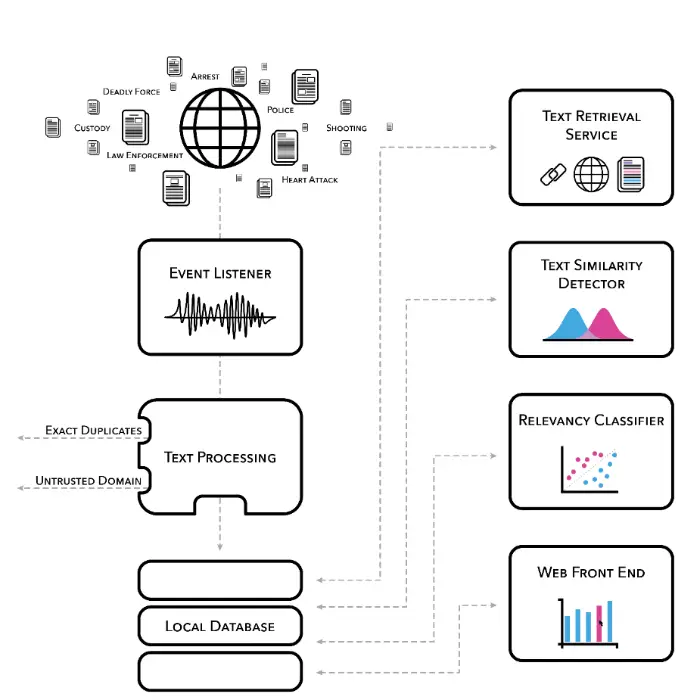
By design, the pipeline efficiently filters out articles it is confident are irrelevant. However, there are many articles that the model is less certain about, and those articles remain. A human coder makes the final determination of whether all remaining articles meet the definition of an arrest-related death and then links multiple articles to a specific decedent, all through a user-friendly web interface (our human coders loved that part—not only fewer articles to review, but no more spreadsheets!).
Once the unambiguously irrelevant articles are discarded by the machine learning classifier, there are less than 10,000 thousand articles a month that need manual review, a manageable number for a small team of human coders. Through these steps, our pipeline achieved over 99 percent reduction in news articles needing manual review, while retaining over 95 percent of decedents (high accuracy rate), allowing RTI to produce a successful proof-of-concept for the first federally sponsored program counting the number of arrest-related deaths in the United States using open-source data. In our study, the media review alone detected 1,348 potential arrest-related deaths during the 10 months covering June 2015 through March 2016, far outpacing the previous methodology.
Maintaining accuracy while reducing human burden were both important in this project. We worked with our client to define the most important accuracy metric (in this case, at least 95% of decedents retained) and implemented checks to ensure our output remained within the acceptable amount of error. We knew we would have to continually retrain our model to maintain good performance on current and future news articles, but we also wanted to avoid biasing the model by training it against its own output. While we focused the majority of manual review on the reduced set of articles produced by our pipeline to maximize efficiency, we also labeled a 1% random sample of all articles monthly, which we used to continually validate our model. We periodically compared the model with human coders by examining a list of cases where the two strongly disagreed. Finally, we merged our results with lists of decedents from multiple external sources to confirm our false negative rate. We identified the cause of any missing decedents and tweaked parameters as necessary to ensure such mistakes would not be repeated.
In December 2016, BJS published our technical report. This project has been featured in numerous media outlets, including The Guardian (2015 and 2016) and fivethirtyeight.com, who also included it among the Best Data Stories of 2016. The system is currently being tested on other police-related outcomes, which provides an opportunity to improve on the existing system as well as realize performance gains from newer deep learning-based approaches for classification.
Gaining Perspective
Our project team, which includes data scientists Jason Nance and Peter Baumgartner, is especially grateful for all of the open source technologies and specifically the Python libraries that made this type of project possible: Python, pandas, spaCy, scikit-learn, Luigi, Keras, nltk, Jupyter, numpy, scipy, TensorFlow, and PostgreSQL.
This project is particularly important for a number of reasons. First, the methodology was successful in standardizing data collection, so that the Justice Department no longer needs to rely on voluntary reporting by local law enforcement. Our system, as reported in The Guardian, is the most comprehensive official effort so far to accurately record the number of deaths at the hands of American law enforcement and provide the “national, consistent data” described by the U.S. Attorney General.
From a broader perspective, I believe data-driven approaches to problem-solving in government are likely to represent the future. Solutions can range anywhere from the traditional (what we think of as primary data collection for research purposes) to unorthodox sources of data (however you define it—found data, digital exhaust) on the other end, to every combination of the two approaches in between. There can potentially be many workable solutions to any given problem. The solution presented here is important because it’s not something we could have done 30 years ago. Societal problems may remain the same, but the solutions are reinvented.
There are many challenges to creating something from scratch in a rapidly moving field in any organization. But it’s worth the effort. RTI’s senior leaders and researchers have been forward thinking and committed to new approaches to problem-solving, which makes my job fun and exciting. Along the way, I’ve learned to embrace ambiguity, experiment, listen, gain trust, and magnify every success. As former President Obama once said, “Nothing in life that’s worth anything is easy.” These are powerful words that I live by and that provide constant inspiration as my team of data scientists and I pursue new ways to use data for good.
This piece was originally published on DataScience.com.
Disclaimer: This piece was written by Gayle Bieler (Senior Director, Center for Data Science and AI) to share perspectives on a topic of interest. Expression of opinions within are those of the author or authors.









