Introduction
Recent advances in machine learning and natural language processing have made text classification (Dwivedi & Arya, 2016) an increasingly popular approach for information retrieval (IR). Text classification models are trained to assign discrete units of text, such as sentences, paragraphs, or full documents, into one of several pre-defined categories by learning from prior labeled observations. Text classification for IR has widespread adoption, with applications as diverse as biomedical systematic reviews (Marshall & Wallace, 2019; Martinez et al., 2008) and legal document retrieval (Moens, 2001; Westermann et al., 2021). An advantage of text classification over non–machine learning IR methods is that models are capable of learning how to categorize text directly from a text’s vocabulary and labels, as opposed to requiring researchers to develop their own rules for how to categorize observations consistently and accurately. Additionally, text classification models can rank observations based on predicted probabilities, allowing users to view observations most likely to be relevant first.
However, despite its popularity, developing text classifiers is challenging when the categories of interest are rare. This is because the normal procedure of drawing a random sample of observations to model on will infrequently return instances of the rare category. This lack of labels from the rare class makes modeling the concept difficult or requires significant effort from the research team to find enough examples to model the rare class effectively. For example, if the underlying prevalence for a rare category is 1 percent, research teams would be required, on average, to label 50,000 observations from a random sample to find 500 examples of the rare category.
Boolean retrieval can be an attractive alternative to text classification for finding instances of rare categories. Boolean retrieval (Manning et al., 2008) is a classical, non–machine learning–based IR technique in which observations containing one or more query terms are returned to the user. These queries are defined using Boolean logic, allowing the user to construct complex rules concerning the presence or absence of terms, or combinations of terms. For example, a Boolean query for finding observations containing the biological term “cell” might contain “(”cell” AND NOT “prison”)” to reduce the chance of returning text related to criminal justice.
An advantage of Boolean retrieval over text classification is that it does not rely on labeled data and, therefore, can return results of rare categories without requiring numerous examples. However, fine-tuning queries can become overwhelming when optimizing for accuracy. When developing queries, there is often a tension between the precise language needed to prevent false positives and the variety of language needed to recall all relevant observations, preventing false negatives. For example, to return a comprehensive set of observations related to soft drinks, an approach designed to minimize false positives may include an exhaustive list of specific name brands or products that would rarely be used outside of the context of soft drinks (e.g., “Coca-Cola,” “Pepsi”). However, these would miss many observations that contain soft drink terminology specific to certain regions of the United States (e.g., “soda” or “pop”). Adding these regional terms would help us capture more soft drink observations, reducing false negatives, but at the expense of potentially including observations that use “soda” or “pop” in a context outside of soft drinks (e.g., “baking soda” or “pop music”), increasing false positives.
In this work, we explore ways of combining the strengths of text classification and Boolean retrieval for finding rare categories in a text corpus. Specifically, we use Boolean retrieval to find candidate labeled examples of rare categories, which we then use to train text classification models. As a motivating example to illustrate this methodology, we will seek to identify all text conversations referencing firearm injury or violence in the Crisis Text Line (CTL) anonymized database from 2018 to 2021.
CTL, one of the largest crisis text services in the United States (Pisani et al., 2022), is a not-for-profit company that provides no-cost, 24–7 confidential crisis counseling via text messaging and WhatsApp. When users of CTL’s service text in, they are paired with trained volunteer Crisis Counselors. The primary goal of these exchanges is to de-escalate the crisis and help the texter reach a point at which they feel calm and safe. Volunteer Crisis Counselors offer mental health support at the time of crisis and, if needed or requested, referrals to community organizations and other accessible resources.
Firearm injuries are a major public health issue and a leading cause of death for individuals ages 1–44 in the United States (Centers for Disease Control and Prevention, 2021). To date, CTL has supported approximately 7 million crisis-related text conversations (Pisani et al., 2022), providing a unique opportunity to better understand the low base-rate event of firearm violence. No study to date has investigated firearm-related text messages within CTL data. Innovative approaches that accurately identify firearm-related texts within all the available CTL messages will critically advance research on firearm violence.
Methods
Data
A conversation between a CTL volunteer Crisis Counselor and texter is made up of a series of text message exchanges. Figure 1 illustrates a fictional abbreviated example of a firearm-related conversation consisting of several messages exchanged between a CTL volunteer Crisis Counselor and texter. For the purposes of this study, a message will refer to a single text message sent by either the texter or volunteer Crisis Counselors, and a conversation will refer to the entire exchange of text messages related to a specific crisis instance from beginning to end.
Figure 1.
155600Fictional abbreviated text exchange between a texter and a volunteer Crisis Counselor

This study uses de-identified English-language CTL message data from August 2018 to September 2021. In August 2018, CTL implemented their “Always Ask” policy, which requires volunteer Crisis Counselors to ask if the texter has had thoughts of suicide as part of each conversation. We chose August 2018 as the start date to capture only data collected while this policy was in effect. Conversations where texters did not engage after being connected with a counselor, along with conversations that led to a ban (i.e., pranks, inappropriate use) were not included in the dataset. Table 1 shows descriptive statistics of the study data.
Approach
Our process of developing text classification models and Boolean queries consists of an iterative workflow (Figure 2) that allows us to refine both the models and firearm keywords over time. This workflow can be decomposed into four main steps: (1) conducting an initial Boolean search of firearm-related keywords to return conversations with a higher likelihood of being the rare class; (2) labeling the results from the initial Boolean queries, training a text classifier, and performing error analysis (repeating as needed to obtain more training data and add more keywords); (3) supplementing labeled data with conversations from outside of the firearm corpus, to improve generalizability; and (4) validating the final text classifier numerous ways.
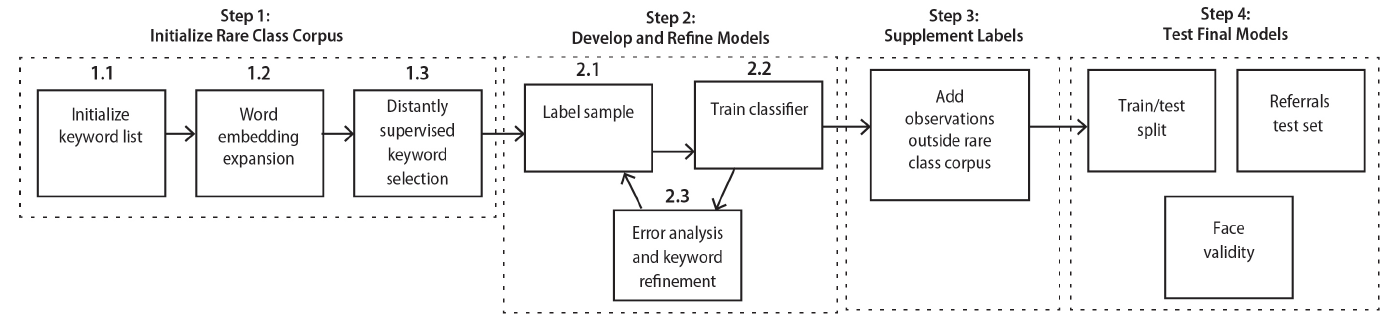
Step 1. Initialize the Rare Class Corpus
Typically, in machine learning, training data are assumed to come from independent and identically distributed draws from the population of interest (Mehryar et al., 2012). However, taking this approach when the category of interest is rare will result in a training set with exceedingly few observations of the rare category, making modeling the concept of interest challenging. To get more observations expected to be of the rare class, we performed a Boolean search using firearm-related terms on the anonymized and de-identified CTL message text to create a firearm corpus (Step 1). Observations from this set were then sampled to create a text classification model with firearm and nonfirearm messages (Step 2.2), with a much higher proportion of the rare firearm-related messages than would be expected under a uniform random sample.
One challenge of taking this approach is that if the keywords used for Boolean retrieval do not fully capture all firearm-related conversations during our study period, the resultant text classification models may perform poorly on the types of firearm conversations that are excluded. Therefore, the main priority in developing the Boolean queries should be to capture as many potential firearm conversations as possible in the firearm corpus (maximize recall), even if it results in false positives (reduced precision). This motivates the need for several ways of expanding firearm-related keywords throughout the iterative workflow (Steps 1.1–1.3, 2.3). While we report details on our approach for creating a set of observations more likely to contain the rare class of interest, not all steps (1.1–1.3) are necessary and can be modified to take advantage of each project’s unique context.
Step 1.1. Create Initial Keyword List
Our initial list comprised 23 firearm-related keywords (see Appendix) obtained from subject matter experts (e.g., “gun,” “shooting”). These terms were added based on prior experience with crisis lines and knowledge of firearm terminology used in research and natural language settings (such as social media). Outside of our case study, developing an initial keyword list may be challenging if the research team is less familiar with the domain or if the concept of interest cannot be cleanly categorized by unique vocabulary alone. Even a cursory exploration of the results returned from an initial Boolean search can be informative in determining the likelihood of success for this approach.
Step 1.2. Word Embedding Expansion
To discover additional firearm-related keywords used by CTL texters, beyond the initial keyword list, we used a word embedding similarity search (Diaz et al., 2016). Word embedding models are a self-supervised learning approach that represents how a term is commonly used in text. Each embedding is a numeric vector, one for each word, that is learned directly from a text collection using an optimization routine. The optimization aims to predict a word based on the context of a small window of adjacent words. One useful property of word embeddings is that terms with similar semantic meaning also tend to be similar numerically. Using a distance or similarity metric, we can designate how similar or dissimilar embeddings are from one another and use this information to find words used in the text conversations in a context similar to those provided in the initial keyword list. The word embeddings for this step were generated using the Word2Vec algorithm (Mikolov et al., 2013) trained on all CTL conversations in our study period. The word embeddings for the 23 terms in the initial set were then compared with their closest matches using the cosine similarity to see if any of the neighboring embeddings were novel firearm-related keywords. This process expanded the number of keyword terms from 23 to 37. The new terms ranged from plurals (i.e., “firearms,” “rifles”) to specific calibers of bullets (“9 mm”).
Step 1.3. Distantly Supervised Keyword Selection
Lastly, we discovered suspected firearm-related conversations using supplementary CTL resources and searched within these to find additional firearm-related keywords. CTL volunteer Crisis Counselors fill out a survey after each conversation. If during the conversation a texter has indicated that they have a plan or access to a means of suicide, volunteer Crisis Counselors complete a free-text field in the post-conversation survey to input what means of suicide the texter indicated. We used this free-text field to identify conversations that contained one of our firearm-related terms and then manually reviewed their associated conversations to identify new candidate keywords. This approach was feasible because there were only 3 months of data available at the time of analysis (the field was added in June 2021) and because the field is only filled out for conversations with a higher suspected suicide risk (N = 814 conversations). This process expanded the keyword list from 37 to 44 terms. Additional keywords added during this process included “gsw,” an abbreviation of “gunshot wound,” and phrases including “shoot myself.”
Although our instantiation of Step 1.3 (i.e., finding select firearm-related conversations and using them to generate keywords) was idiosyncratic to this case study, the broader approach of opportunistically finding examples of the outcome of interest and using those to develop features, or using them as labeled data, is not uncommon in the machine learning literature. In particular, distant supervision (Mintz et al., 2009), using an external data source to infer labels for an unlabeled sample, inspired our approach for this step. Although distant supervision is primarily used in the literature to generate labeled data, we modified the approach to support Boolean retrieval, allowing us to take full advantage of available CTL resources.
Step 2. Develop and Refine Text Classification Models on Rare Class Corpus
Despite having a corpus of firearm-related conversations in which each conversation contains at least one firearm keyword (Step 1), not all conversations in the corpus are about firearms, or more specifically, about firearm violence. To address this, the goal of Step 2 is to have coders label samples from this firearm corpus (Step 2.1) for two purposes: (1) to train text classification models that will allow us to classify a more specific category of firearm violence (Step 2.2), and (2) to find more relevant firearm keywords by assessing disagreements between the text classifier and labeled examples (Step 2.3). This process of expanding the firearm corpus, labeling data from the firearm corpus, and refining text classification models to better filter false positive observations is repeated over several rounds with the goal of developing a final text classifier that can then be applied to all 2.5 million conversations in our study period.
Step 2.1. Label Firearm Messages
The labeling process consisted of categorizing individual messages within a conversation based on their applicability to firearm violence. Human coders were asked to classify messages into one of three categories: “Applicable Mention of Firearm Violence” (AMF), “Nonapplicable Mention of Firearms” (NMF), or “No Mention” (NM). Our main category of interest, AMF, was used to identify all applicable mentions of firearms in which someone used, was using, or was considering using a firearm to harm or threaten any person. Messages were coded individually based on explicit statements and not on what might have been implied and required interpretation. Table 2 further describes the labeling options for the AMF code.
Table 2.
155603Firearm category definitions used for labeling
Across the iterations of this step, a team of four coders (CO, BD, AB, SL) labeled a total of 1,200 conversations, labeling each message in the conversation. Most conversations were labeled by only one coder, except for 40 conversations per round of 400 conversations that were labeled by all coders to assess inter-rater reliability. The percent agreement across coders on the sample was 93.3 percent. Gwet’s AC1 (Gwet, 2008) was used as an additional metric to adjust for chance coding (AC1 = 0.929) because it does not suffer from the “high agreement, low reliability” paradox sometimes experienced with other common reliability metrics (Falotico & Quatto, 2015; Feng, 2015; Zhao et al., 2013).
Step 2.2. Train Firearm Text Classifier
Text classification models were created using the training data generated by the labeling process. The three-level AMF coding was transformed into a binary target by combining codes NMF and NM. The final binary classification model’s target was AMF (1 = AMF, 0 = No AMF). The model was developed using spaCy (Montani et al., 2021), a natural language processing Python package. Specifically, we use spaCy’s TextCatEnsemble model, which combines a neural network model and a linear bag-of-words model via a stacked ensemble. The model produces a predicted probability that each message is firearm-related (AMF). A threshold of 0.5 was used to transform the probability into a binary label, with over 0.5 designated as an AMF. The performance for the final text classification model can be found in the results section.
Step 2.3. Error Analysis and Keyword Refinement
Error analysis (Ng, 2022) is the process of analyzing misclassified examples for the purpose of improving the model or fixing mislabeled data. For our use case, this included manually reviewing (1) cases in which the model predicted the message to be an AMF but the coder did not classify it as such; (2) cases in which the model predicted the message to be not an AMF but both the coder and Boolean search classified it as an AMF; and (3) cases in which the classifier and coder agree on the AMF designation, but the designation was missed by the Boolean search. Scenario (3) is possible because each firearm conversation contains both firearm and nonfirearm messages and both text classification and keyword matches were assigned at the message level. Most changes resulting from the error analysis were to either add keywords (e.g., “shoot [pronoun]”) or change labels that were misapplied by coders. It also provided insight into common scenarios in which the Boolean retrieval, and sometimes text classifier, struggled (e.g., idioms such as “jumping the gun” or mentions of recreational gun use).
Based on insights from the error analysis, we repeated the earlier components of Step 2, adding new keywords and Boolean logic to extend the number of potential AMF conversations. We then labeled new conversations based on this extended corpus, re-trained the AMF classifier, and performed error analysis. We stopped this cycle after three rounds, using a combination of model performance and error analysis feedback as a stopping criterion. Repeating this process added 79 new keyword combinations to the Boolean query (total of 123). Table 3 depicts the growth in the number of conversations returned from Boolean retrieval after each modification to the keyword list.
Table 3.
155604Volume of messages and conversations returned from Boolean retrieval
Step 3. Supplement with Labeled Data Outside of the Rare Class Corpus
Although labeled data from the firearm corpus is useful for finding examples of the rare class to train on, because we only labeled messages in conversations returned from the Boolean queries, the models were only able to learn from messages and conversations from the firearm corpus. Although this process is designed to iteratively expand the firearm corpus throughout, we could systematically miss a portion of firearm conversations if our keywords were not extensive enough. Furthermore, if messages outside of the firearm corpus were substantively different than those in the firearm corpus, there are no guarantees that the model would be able to accurately predict the nonfirearm corpus conversations well.
As a final modeling step, we addressed these issues by labeling additional messages from conversations not included in the firearm corpus. While we could draw a uniform random sample of these conversations to label, this would return mostly nonfirearm conversations because the chance of randomly selecting a firearm conversation that does not already contain a firearm keyword is small. As an alternative, we used the current text classifier to predict on the conversations that were not part of the firearm corpus and created two groups: (1) those that were not in the firearm corpus and predicted as AMF = 1; and (2) those that were not in the firearm corpus and predicted as AMF = 0. We then drew a stratified random sample of 400 conversations across these groups to label. We did not share with the coders to which strata the conversations belonged, to avoid influencing their labeling decisions.
Conversations that were not in the firearm corpus and predicted as AMF = 1 are conversations that the text classification model believed were relevant but that did not contain a firearm keyword. Human feedback on these predicted labels is valuable for improving the text classification model because it will both expose instances where the model predictions are incorrect while also reinforcing correctly predicted observations. Conversations that were not in the firearm corpus and predicted as AMF = 0 were expected to overwhelmingly be nonfirearm related, since they were neither predicted to be AMF nor did they contain a firearm keyword. However, they were important to include in the training and test sets since nonfirearm conversations comprised most conversations in our study period, and we wanted to confirm that the final model could correctly classify them as AMF = 0.
Step 4. Test Final Model
We performed three evaluations to test our final models:
Model Comparison. Compared the performance of the final Boolean retrieval and text classification models on a random sample of the labeled data.
Model Validation—Independent Test Set. Tested the performance of the final text classification model on set of AMF conversations, generated independently from our firearm corpus approach.
Model Validation—Face Validity. Tested our assumption that the final text classification model would identify more AMF conversations than an initial Boolean search. We also compared the number of conversations predicted as AMF = 1 by the text classifier with the number returned in the expanded Boolean search.
Model Comparison
To compare the final text classification and Boolean retrieval approaches, we assessed both on a hold-out test set of a random 20 percent of the labeled data not used for training (N = 320). We calculated the class-specific precision, recall, and F1 score, as well as the overall accuracy for both models.
Model Validation—Independent Test Set
For validation, we created a final test set of conversations about firearm violence generated from CTL’s operations, entirely independent from our approach. Performing well on this set should give us greater assurances that our model can find conversations related to firearm injury and violence that are not dependent on the choices made in constructing the firearm corpus.
To validate our final text classification model, we used conversations containing referrals to resources related to mass shootings and gun violence as our independent test set. Resource referrals are materials shared with texters by volunteer Crisis Counselors as a means of extra support following the conversation. These referral resources provide additional information and support on a variety of topics such as suicide, gun violence, coping strategies, and domestic violence. The firearm-related referrals shared in conversations by volunteer Crisis Counselors in our study period are both from the Everytown for Gun Safety Support Fund (Everytown Support Fund, 2022):
Trauma and Gun Violence, which is described to volunteer Crisis Counselors as a referral that “provides information on combating gun violence, coping with the aftermath of a mass shooting, and has a forum for survivors.”
Everytown Support Fund, which is described to volunteer Crisis Counselors as a “Trauma and Gun Violence sheet [that] explains trauma after gun violence and shares coping skills.”
This independent test set does not contain observations from the labeled training or validation sets used to develop the text classifiers.
Model Validation—Face Validity
Based on our mental model of how text classification should interact with the Boolean retrieval, we hypothesized that the text classification model would result in more AMF conversations than the initial keyword list, because it was built using a more extensive set of expected firearm-related messages. We also hypothesized that the text classification model would identify more AMF conversations if it performed vastly better than the final Boolean query, with the quantity returned by both converging as the gap in performance shrinks. To test this hypothesis, we estimated the number of AMF conversations using the original keywords, final keywords, and the final classification model on all conversations within the study period.
Results
Model Comparison
To compare the final text classification and Boolean retrieval approaches, we assessed both on a hold-out test set of a random 20 percent of the labeled data not used for training (N = 320). Our results, summarized in Table 4, show that the text classification model outperforms Boolean retrieval on most model performance metrics. Notably, we observed higher precision for AMF = 1 (0.92 vs 1.00), higher recall for AMF = 0 (0.81 vs 1.00), and higher overall accuracy (0.93 vs 0.96). The text classifier also outperformed Boolean retrieval for both classes when assessed using the F1 score (AMF = 0: 0.89 vs 0.94; AMF = 1: 0.95 vs 0.97). Boolean retrieval outperformed the text classifier in precision for AMF = 0 (0.98 vs 0.89) and recall for AMF = 1 (0.99 vs 0.95).
Table 4.
155605Performance of the final Boolean retrieval and text classification model
| Type | AMF Label | N | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|---|
|
Boolean Retrieval (Keywords = 123) |
0 | 101 | 0.98 | 0.81 | 0.89 | 0.93 |
| 1 | 219 | 0.92 | 0.99 | 0.95 | ||
| Text Classifier | 0 | 101 | 0.89 | 1.00 | 0.94 | 0.96 |
| 1 | 219 | 1.00 | 0.95 | 0.97 |
Note: AMF = Applicable Mention of Firearm Violence.
Model Validation
To validate the final model, we used referrals given to texters by volunteer Crisis Counselors as an independent test set. In our study period, there were 57 conversations in which a volunteer Crisis Counselor shared a gun violence-related referral, indicating the conversation was likely firearm-related. After coding, 54 of the conversations were found to be firearm related. Of the 54 conversations, the final model labeled at least one message in 49 of these conversations as an AMF, for a recall of 91 percent.
As a final test of face validity, we calculated the number of AMF conversations found using the original keywords, final keywords, and the final classification model. Table 5 summarizes the estimated number of AMF conversations in our study period using all three approaches. The final text classification model identified 2.82 percent of conversations (N = 71,839) in our study period as AMF conversations, compared with only 2.07 percent (N = 52,461) of conversations in our study period returned by the initial keywords and 2.75 percent (N = 69,770) of conversations returned by the final keyword list.
Table 5.
155606Estimated number of AMF conversations in study period using the initial Boolean search, final Boolean search, and final text classification model
| Type | AMF Conversations | |
|---|---|---|
| (N) | (%) | |
| Initial Boolean Retrieval (Keywords = 23) | 52,461 | 2.07% |
| Final Boolean Retrieval (Keywords = 123) | 69,770 | 2.75% |
| Final Text Classification Model | 71,839 | 2.82% |
Note: AMF = Applicable Mention of Firearm Violence.
Discussion
Text classification with Boolean retrieval initialization was effective in creating a refined set of AMF conversations, a rare class that was initially expected to only appear in roughly 2 percent of all CTL conversations. These models outperformed an iterative Boolean retrieval process and were better able to distinguish between when the firearm keywords indicated an AMF and when they were used in other contexts. This was demonstrated on both an adaptively constructed set of conversations and a separate test set of conversations containing gun violence resource referrals. Our use of the gun violence resource referrals as an external test set allowed us to assess this approach on observations generated from a different mechanism than the firearm keywords, providing additional support for the method.
The test of face validity confirmed our hypothesis that the final text classifier would identify more conversations as AMF = 1 than were returned by the initial keyword list and would return a similar number of conversations to the final keyword list if their performance was similar. Although the text classifier outperformed the final Boolean retrieval overall, the iterative development process allowed both to perform well at identifying AMF. Furthermore, the iterative nature of this process demonstrated value in finding instances of the rare class, given that the final estimate of AMF conversations (N = 71,839) is well above the initial estimate using only keywords from subject matter experts (N = 52,461). Being able to identify rare categories, such as firearm violence and injury, can improve crisis lines’ abilities to support people with firearm-related crises or provide appropriate resources more accurately.
This approach is designed to be flexible and allow teams to take advantage of project-specific resources. For example, we added Step 1.3 because we had access to tables with relevant information that could be used to refine the Boolean queries; while this provided more ideas for increasing the size of the firearm corpus, the approach could still be implemented without this step given the multitude of other ways for developing Boolean queries (e.g., Steps 1.1 and 1.2). Additionally, while we focused on firearm injury and violence as a motivating example, our approach could be extended to any rare class in which domain knowledge can be used to identify positive cases at least partially. Although we only explored binary classification, this approach could also be expanded to multi-class classification by creating different Boolean queries for each rare class and drawing stratified samples across the rare classes to label. In our use case, each conversation in the firearm corpus often consisted of both firearm and nonfirearm messages. Since we were building text classification models at the message level, this reduced the need for labeling nonfirearm conversations at the outset because there were already both firearm and nonfirearm messages available for training from the conversations in the firearm corpus. In cases where the unit of analysis does not exhibit this hierarchy, documents outside the rare class corpus should be incorporated sooner.
Although the final text classification model improved upon the accuracy of the Boolean query, depending on the goals of the analysis, an iterative Boolean retrieval process as described above may be an attractive alternative if sufficient resources are not available to support text classification. Supervised machine learning methods require labeled data both to assess the method and to train the model. The labor required to generate these additional labels may not be worth the effort if there are competing budget or time constraints or if the intended use case has a higher tolerance for misclassification. Boolean retrieval also benefits from being fast to apply at inference time and being transparent in how it makes classification decisions. Especially when the category of interest is rare, it may be prudent to start with assessing the performance of a modified Boolean retrieval process to determine whether adding text classification would benefit the project.
Related Work
Given the ubiquity of the methods, several papers have compared the performance of Boolean retrieval and text classification. Turtle (Turtle, 1994) compares natural language query techniques to Boolean retrieval for searching full-text legal materials and finds that the natural language systems outperform expert-crafted Boolean queries. Cohen et al (Cohen et al., 2006). also compare text classification to a search query approach and find that for most topics studied, text classification improved precision while keeping competitive recall. More recently, Westermann et al (Westermann et al., 2021). compare Boolean search to several machine learning methods, such as random forests (Breiman, 2001), support vector machines (Cortes & Vapnik, 1995), and a linear model using fastText (Bojanowski et al., 2017) embeddings. They similarly find that text classification methods outperform Boolean queries, while they also acknowledge that Boolean search benefits from being highly interpretable. Although these studies do not attempt to combine text classification with Boolean retrieval, our overall findings agree with these prior works and suggest that text classification outperforms Boolean retrieval, even in the setting of rare categories.
Using domain knowledge to develop queries that are more likely to contain the class of interest is common in data programming (Ratner et al., 2016). Data programming is a weak supervision method that consists of three steps: (1) developing labeling functions to programmatically encode domain knowledge about the categories of interest; (2) combining the output of the labeling functions using a generative model to develop a best-guess estimate of the true class label; and (3) using the estimated class labels to train a supervised machine learning model. When the data modality is text, keyword-based Boolean queries such as those used in this work are often employed as labeling functions. Future work could extend our approach to incorporate ideas from data programming, such as training a generative model from the individual Boolean queries for each keyword to create a more refined rare class corpus.
A final related research area comprises methods for finding instances of rare classes to support classification. The majority of these efforts use active learning (Settles, 2012), a subdomain of supervised machine learning that iteratively uses model feedback to recommend which observations to label next. Pelleg & Moore (Pelleg & Moore, 2004) propose an active learning strategy that allows the component of a mixture model to “nominate” its favorite queries to find extremely rare classes in the presence of noise. Although this method assumes a mixture model to fit the data, it does not require a particular functional form for the mixture components. Hospedales et al (Hospedales et al., 2013). have developed an active learning strategy to jointly address classification and rare class discovery, a challenging setting in which the target classes of interest are unknown a priori. They propose a generative-discriminative model pair to combine the discovery properties of generative models with the superior classification properties of discriminative models. Mullapudi et al (Mullapudi et al., 2021b). propose an active semi-supervised method that incorporates techniques for learning under extremely imbalanced data for images (Mullapudi et al., 2021a) to label the “easy” negative examples, leaving the “hard” examples for human labelers. Lastly, closest to our work, Attenberg & Provost (Attenberg & Provost, 2010) compare using a search strategy to initialize a model with examples of the rare class to using popular active learning strategies. They also propose a hybrid model that uses search strategies (e.g., Boolean retrieval) to initialize an active learning model. They find the hybrid approach shares attractive properties of both the search and active learning strategies and outperforms both individually. Of the literature for finding instances of rare categories for classification, this work is the most like ours, in that both use search methods to find cases of the rare class to initialize a model and then perform iterations of model refinement. Our work helps clarify that this general approach can be effective even when not using active learning and provides comparisons to an iterative Boolean retrieval process.
Study Limitations
Results from our study should be interpreted within the context of several limitations. One limitation is that it is infeasible to determine exactly how many firearm conversations are in the CTL database for the study period. While our evaluation metrics suggest that the final text classification model outperforms keyword-based retrieval, the exact number of AMF conversations is still unknown and would be difficult to confirm outside of full enumeration. Another limitation is that the conversations are scrubbed of personally identifiable information by CTL before our use. Although this is effective in preventing disclosure of a texter’s personal information, the algorithm may on occasion mistakenly redact language that contains firearm-related keywords. Additionally, including redactions in conversations while modeling may affect performance, although our error analysis suggests this impact is minor. The firearm-related resources shared during our study period include only referrals to organizations that focus on gun violence prevention. This scope provides less insight into model performance on other firearm-related crises, such as firearms as a means for suicide. Lastly, while we present a multi-step approach in this work, we did not have the resources to conduct an ablation study to better understand how each individual component contributed to the overall success of the method. Future work could embrace this focus, as well as replicate the approach across different datasets to better understand under which conditions it is more or less likely to be beneficial.
Conclusion
Creating text classifiers from scratch can be challenging when the category of interest is rare. In this work, we develop an approach that combines strengths from text classification and Boolean retrieval to find instances of rare categories, using the goal of finding all firearm violence conversations in the CTL database between 2018 and 2021 as a motivating case study. Identifying rare categories, like firearm violence and injury, can improve crisis lines’ abilities to support people with firearm-related crises or provide appropriate resources. We find that this approach improved on a refined Boolean search alone and returned nearly 20,000 more relevant cases than an initial Boolean search using only terms provided by subject matter experts. Research teams requiring high-quality results should consider text classification with Boolean retrieval initialization for detecting rare categories of interest.
















