Stepping Up to the CORD-19 Challenge: A Semi-Automated Rapid Review Workflow for Literature Related to COVID-19 and Blood Clotting




As the COVID-19 pandemic continues, researchers around the world are rapidly publishing new findings related to the virus. The growing body of research creates challenges for health professionals trying to assimilate new evidence efficiently and accurately into their current understanding of the virus, including its behavior, treatment, and risk factors.
To address this challenge, the White House and a group of leading research organizations released the COVID-19 Open Research Dataset Challenge (CORD-19) on the Kaggle machine learning competition platform, providing several discrete tasks for AI practitioners in the general public to tackle. With RTI’s mission being to improve the human condition by turning knowledge into practice, we funded a team of two data scientists and a microbiologist/immunologist to prepare a submission for the task of automatically extracting key information from papers related to the increased risk of blood clotting, seen in 20-30% of COVID-19 patients.
COVID-19 is best known for its direct impacts on the respiratory system, but it can also cause complications across a range of organ systems including the gastrointestinal tract, nervous system, liver and kidneys. Non-respiratory symptoms range from vomiting to a loss of smell.
A tendency for blood to become sticky, or hypercoagulable, precedes blood clot formation and can be especially dangerous to COVID-19 patients, since it can exacerbate the effects of compromised lung function. An emerging hypothesis is that clots in tiny lung air sacs restrict movement of oxygenated blood, thereby compounding the severity of reduced lung capacity associated with pneumonia. Such a scenario would help explain why some people benefit from receiving oxygen rather than the use of mechanical ventilators.
It is currently unclear why the hypercoagulable state occurs in some COVID-19 patients and not others. One possibility is that the virus attacks blood vessel cells via the same ACE2 receptor known to mediate lung infection. Damaged blood vessels could be releasing factors that increase clotting tendency.
To address the hypercoagulable state, physicians have been treating COVID-19 patients with blood thinners known as anti-coagulants and have seen mixed benefit to patients. The best dosing regimens are unknown, and clinicians must monitor for consequences associated with excessive bleeding in the event the prescribed blood thinner dosage is too high.
Despite the known danger, little is known about the best way to combat the blood clotting response seen in COVID-19 and while many reports are being published, information synthesis is a challenge.
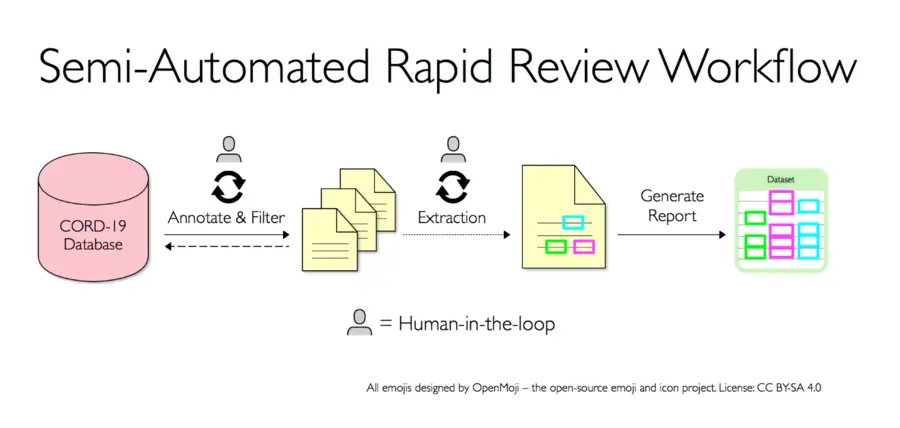
The RTI Center for Data Science team developed an iterative, semi-automated workflow for key components of a rapid systematic review to collect evidence on treatments for the hypercoagulable state seen in COVID-19.
Systematic reviews are a comprehensive and transparent method for synthesizing evidence from the published literature. What primarily distinguishes systematic reviews from other types of literature reviews is the level of detail and thoroughness; researchers involved in systematic reviews take painstaking care into developing a precise review question, inclusion and exclusion criteria, search strategy, assessments of study quality, and synthesis of results (often in the form of a formal meta-analysis).
Rapid reviews are a timely alternative when a full systematic review is too resource or time intensive to conduct. For example, systematic reviews often take 12-24 months to complete, whereas rapid reviews can be completed in a matter of weeks. Rapid reviews attempt to balance the need for systematic and transparent methods with expediency by simplifying the review components. This may include reducing the number of databases for search, assigning a single reviewer in each step while another reviewer verifies the results, excluding grey literature, or narrowing the scope of the review.
RTI’s submission dealt with two fundamental components of a rapid review:
Our approach applied two natural language processing (NLP) methods to perform filtering and extraction. We first used scispacy, a Python library with a built-in entity linker, to annotate phrases in the text with known biological concepts in the UMLS controlled vocabulary. We then applied scispacy’s advanced probabilistic language model to parse dependencies within sentence structure in the text, identifying relationships between various concepts. We combined these approaches in various ways to filter papers of interest and extract relevant concepts with their context for the rapid review.
As of the submission date, 206 out of nearly 70,000 COVID-19 related papers were identified as relating to both COVID-19 and hypercoagulability. Our process extracted concepts from this subset of papers including sample size, study type, outcomes, and primary endpoint. While the specific task is to extract various information related to hypercoagulability and COVID-19, this approach taken more broadly could be applied to any rapid systematic review process.
Our iterative workflow offers several benefits to clinicians and researchers evaluating evidence from peer-reviewed studies:
Despite these advantages, automating systematic reviews is far from a solved problem, and there are several areas for improvement. For example, our work does not tackle other important aspects of rapid reviews such as a risk of bias assessment, reliability checks by multiple reviewers, or a meta-analysis. Given the CORD-19 challenge did not have a targeted PICO statement defining the intended population, interventions, or outcomes of interest, we felt these steps would be better addressed in future work supported by domain experts and systematic review methodologists.
More generally, rapid reviews trade-off certainty for speed and may not be appropriate for every topic, since the extent of bias introduced by taking an expediated approach is unknown. Furthermore, these methods should not be expected to provide a perfect selection of studies or extraction of key concepts. Subject matter expertise is invaluable for interpreting, evaluating, and contextualizing output from this workflow; ideally, this process will be the first, rather than the only, step researchers will take in collecting and synthesizing evidence on the timely issues of our times.
Learn more about RTI’s research and response surrounding the COVID-19 crisis and check out our AI Emerging Issues page for our capabilities related to emerging technologies.









